The recent success in StyleGAN demonstrates that pre-trained StyleGAN latent space is useful for realistic video generation. However, the generated motion in the video is usually not semantically meaningful due to the difficulty of determining the direction and magnitude in the StyleGAN latent space.
In this paper, we propose a framework to generate realistic videos by leveraging multimodal (sound-image-text) embedding space. As sound provides the temporal contexts of the scene, our framework learns to generate a video that is semantically consistent with sound.
First, our sound inversion module maps the audio directly into the StyleGAN latent space. We then incorporate the CLIP-based multimodal embedding space to further provide the audio-visual relationships. Finally, the proposed frame generator learns to find the trajectory in the latent space which is coherent with the corresponding sound and generates a video in a hierarchical manner.
We provide the new high-resolution landscape video dataset (audio-visual pair) for the sound-guided video generation task. The experiments show that our model outperforms the state-of-the-art methods in terms of video quality. We further show several applications including image and video editing to verify the effectiveness of our method.
Method
Train
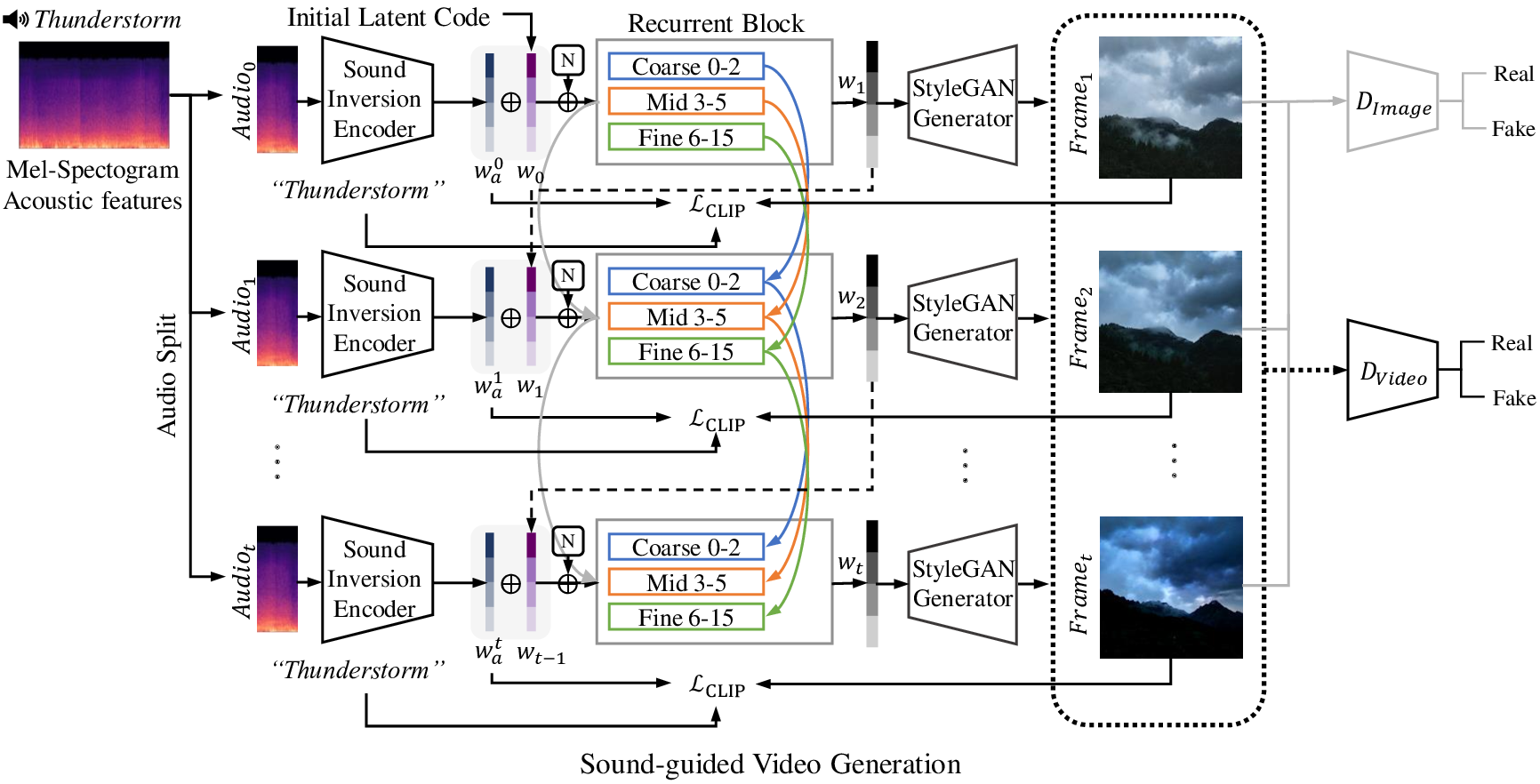
Fig5. An overview of our sound-guided video generation model, which consists of two main parts: (i) Sound Inversion Encoder, which iteratively generates sound-conditioned latent code ${\bf{w}}_a^t$ from corresponding audio time segments. (ii) StyleGAN-based Video Generator, which recurrently generates a video frame that is trained to be consistent with neighboring frames. Moreover, we train image and video discriminators adversarially
to generate perceptually realistic video frames.
Inference
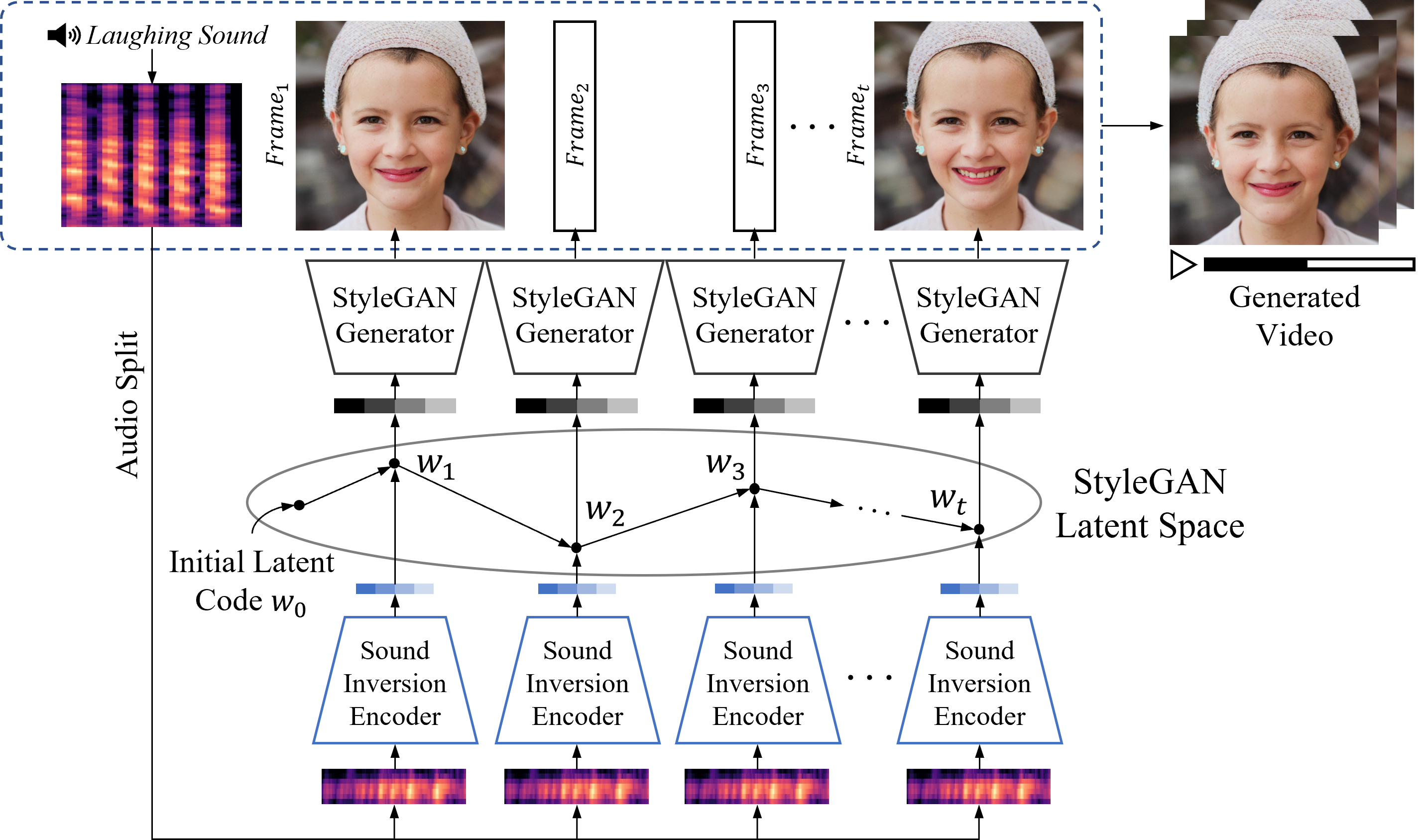
Fig3. An overview of our proposed sound-guided video generation model. Our model consists of two main modules:
(i) Sound Inversion Encoder (Section 3.1), which takes a sequence of audio inputs as an input and outputs a latent code to generate video frames. (ii) StyleGAN-based Video Generator (Section 3.2), which generates temporally consistent and perceptually realistic video frames conditioned on the sound input.